- 浏览: 1168911 次
- 性别:

- 来自: 北京
-

文章分类
- 全部博客 (350)
- Ajax研究 (2)
- javascript (22)
- struts (15)
- hibernate (12)
- spring (8)
- 我的生活 (28)
- jsp (2)
- 我的随笔 (84)
- 脑筋急转弯 (1)
- struts2 (2)
- ibatis (1)
- groovy (1)
- json (4)
- flex (20)
- Html Css (5)
- lucene (11)
- solr研究 (2)
- nutch (25)
- ExtJs (3)
- linux (6)
- 正则表达式 (2)
- xml (1)
- jetty (0)
- 多线程 (1)
- hadoop (40)
- mapreduce (5)
- webservice (2)
- 云计算 (8)
- 创业计划 (1)
- android (8)
- jvm内存研究 (1)
- 新闻 (2)
- JPA (1)
- 搜索技术研究 (2)
- perl (1)
- awk (1)
- hive (7)
- jvm (1)
最新评论
-
pandaball:
支持一下,心如大海
做有气质的男人 -
recall992:
山东分公司的风格[color=brown]岁的法国电视[/co ...
solr是如何存储索引的 -
zhangsasa:
-services "services-config ...
flex中endpoint的作用是什么? -
来利强:
非常感谢
java使用json所需要的几个包 -
zhanglian520:
有参考价值。
hadoop部署错误之一:java.lang.IllegalArgumentException: Wrong FS
接上篇博客写的.今天现简单介绍下hadoop的运行原理.
hadoop的配置在这里我就不详细讲了,网上关于这方面的文章很多,有单机版的,也有集群的。
hadoop主要由三方面组成:
1、HDFS
2、MapReduce
3、Hbase
Hadoop框架中最核心的设计就是:MapReduce和HDFS。MapReduce的思想是由Google的一篇论文所提及而被广为流传的, 简单的一句话解释MapReduce就是“任务的分解与结果的汇总”。HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写 ,为分布式计算存储提供了底层支持。
MapReduce从它名字上来看就大致可以看出个缘由,两个动词Map和Reduce,“Map(展开)”就是将一个任务分解成为多个任 务,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。这不是什么新思想,其实在前面提到的多线程,多任务的设计就可以找到这 种思想的影子。不论是现实社会,还是在程序设计中,一项工作往往可以被拆分成为多个任务,任务之间的关系可以分为两种:一种是不相关的任务,可以并行执 行;另一种是任务之间有相互的依赖,先后顺序不能够颠倒,这类任务是无法并行处理的。回到大学时期,教授上课时让大家去分析关键路径,无非就是找最省时的 任务分解执行方式。在分布式系统中,机器集群就可以看作硬件资源池,将并行的任务拆分,然后交由每一个空闲机器资源去处理,能够极大地提高计算效率,同时 这种资源无关性,对于计算集群的扩展无疑提供了最好的设计保证。(其实我一直认为Hadoop的卡通图标不应该是一个小象,应该是蚂蚁,分布式计算就好比 蚂蚁吃大象,廉价的机器群可以匹敌任何高性能的计算机,纵向扩展的曲线始终敌不过横向扩展的斜线)。任务分解处理以后,那就需要将处理以后的结果再汇总起 来,这就是Reduce要做的工作。
下面这个图很经典:
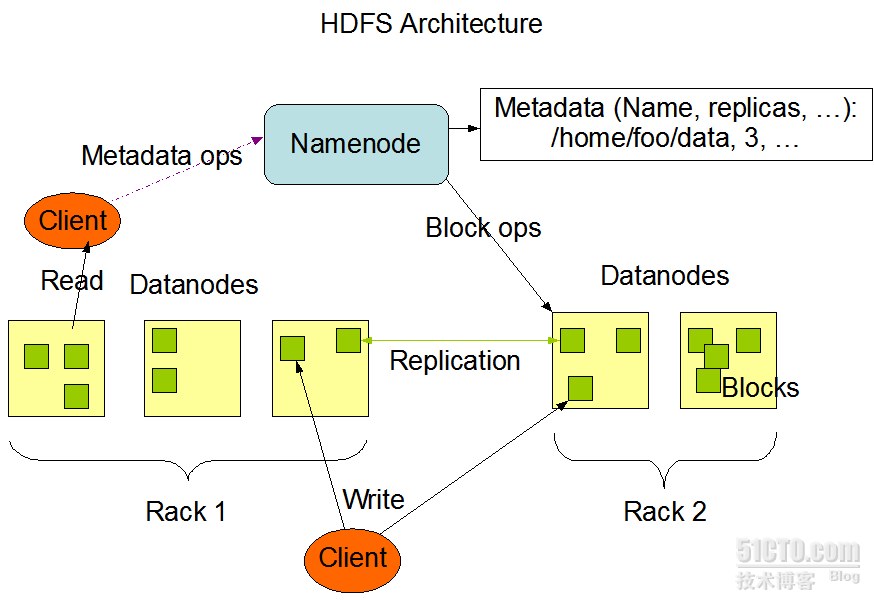
文件写入:
a):Client向NameNode发起文件写入的请求。
b):NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
c):Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
文件读取:
a):Client向NameNode发起文件读取的请求。
b):NameNode返回文件存储的DataNode的信息。
c):Client读取文件信息。
文件Block复制:
a):NameNode发现部分文件的Block不符合最小复制数或者部分DataNode失效。
b):通知DataNode相互复制Block。
c):DataNode开始直接相互复制.
下面综合MapReduce和HDFS来看Hadoop的结构:

Hadoop结构示意图
在Hadoop的系统中,会有一台Master,主要负责NameNode的工作以及JobTracker的工作。JobTracker的主要职责 就是启动、跟踪和调度各个Slave的任务执行。还会有多台Slave,每一台Slave通常具有DataNode的功能并负责TaskTracker的 工作。TaskTracker根据应用要求来结合本地数据执行Map任务以及Reduce任务。
LOG.info(tempJobName + " data start .....");
tempJob.setJarByClass(tempMain.class); //设置这个Job运行是那个类
tempJob.setMapperClass(MultithreadedMapper.class); //设置这个job运行的map,这里面使用了本身map自带的多线程实 现机制,这一点很重要,可以帮助我们提高运行的效率。
MultithreadedMapper.setMapperClass(tempJob,tempMapper.class); //设置这个job运行的map
MultithreadedMapper.setNumberOfThreads(tempJob, Integer.parseInt(tempThread));//设置多线程运行几个线程
tempJob.setMapOutputKeyClass(LongWritable.class);// 设置map所输出的key
tempJob.setMapOutputValueClass(StringArrayWritable.class); // 设置map所输出的value
...... //下面还有reduce的一些,我这里的业务没有涉及到,这里就不列出来了。
long start = System.currentTimeMillis();
boolean result = tempJob.waitForCompletion(true); //启动一个job运行
long end = System.currentTimeMillis();
顶
踩


评论
发表评论

-
Java并发编程总结---Hadoop核心源码实例解读
2012-04-01 15:46 2105程序设计需要同步(synchronization),原因:1) ... -
使用hadoop的lzo问题!
2011-08-24 17:12 2579使用lzo压缩替换hadoop原始的Gzip压缩。相比之下有如 ... -
secondarynamenode配置使用总结
2011-07-07 08:37 7462一、环境 Hadoop 0.20.2、JDK 1.6、Lin ... -
Map/Reduce中的Combiner的使用
2011-07-07 08:36 4724一、作用 1、combiner最基本是实现本地key的聚合, ... -
Map/Reduce中的Partiotioner使用
2011-07-07 08:35 1811一、环境 1、hadoop 0.20.2 2、操作系统Li ... -
hadoop如何添加节点
2011-07-06 12:43 14491.部署hadoop 和普通的datanode一样。安装 ... -
hadoop如何恢复namenode
2011-07-06 12:36 8485Namenode恢复 1.修改conf/core-site.x ... -
Hadoop删除节点(Decommissioning Nodes)
2011-07-06 11:52 24971.集群配置 修改conf/hdfs-site.xml ... -
hadoop知识点整理
2011-07-06 11:51 26331. Hadoop 是什么? Hadoop 是一种使用 Ja ... -
喜欢hadoop的同学们值得一看
2011-07-03 15:50 1978海量数据正在不断生成,对于急需改变自己传统IT架构的企业而 ... -
hadoop优化
2011-07-03 15:43 1307一. conf/hadoop-site.xml配置, 略过. ... -
hadoop分配任务的问题
2011-05-16 23:09 5请教大家一个关于hadoop分配任务的问题: 1、根据机器 ... -
hadoop-FAQ
2011-05-15 11:38 704hadoop基础,挺详细的。希望对大家有用! -
Apache Hadoop 0.21版本新功能ChangeNode
2011-04-21 22:04 1942Apache Hadoop 0.21.0 在2010年8月23 ... -
Hadoop关于处理大量小文件的问题和解决方法
2011-04-21 11:07 2457小文件指的是那些size比 ... -
hadoop常见错误及解决办法!
2011-04-07 12:18 96378转: 1:Shuffle Error: Exceede ... -
Hadoop节点热拔插
2011-04-07 12:16 1595转 : 一、 Hadoop节点热 ... -
hadoop动态添加节点
2011-04-07 12:14 1975转: 有的时候, datanode或者tasktrac ... -
欢迎大家讨论hadoop性能优化
2011-04-06 15:42 1256大家知道hadoop这家伙是非常吃内存的。除了加内存哦! 如 ... -
hadoop错误之二:could only be replicated to 0 nodes, instead of 1
2011-02-22 08:23 2315WARN hdfs.DFSClient: NotReplic ...
相关推荐
一个hadoop的简单介绍,可以让刚刚入门的同学们对hadoop有一个大概的了解。
Hadoop运行原理分析pdf
Hadoop运行原理分析
在hadoop平台上,实现词频统计(WordCount),指令很详细
HDFS概述,HDFS客户端操作,HDFS数据流,namenode工作机制,datanode工作机制,HDFS 高可用集群配置
讲述大数据工具-Hadoop运行架构及原理,全局掌握Hadoop。
对hadoop的hdfs,mapreduce,yarn三大模块的内部运行原理进行总结和归纳,了解其内部的原理
Hadoop介绍,HDFS和MapReduce工作原理
(1)熟悉Hadoop开发包 (2)编写MepReduce程序 (3)调试和运行MepReduce程序 (4)完成上课老师演示的内容 二、实验环境 Windows 10 VMware Workstation Pro虚拟机 Hadoop环境 Jdk1.8 二、实验内容 1.单词计数实验...
3. 学会在Spark Shell中运行Scala程序。 二、实验环境 Windows 10 VMware Workstation Pro虚拟机 Hadoop环境 Jdk1.8 三、实验内容 (一)Spark基础知识 (1)输入start-all.sh启动hadoop相应进程和相关的端口号 (2...
简介HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。是根据google发表的论文翻版的。论文为GFS(Go
使用hadoop实现WordCount详细实验报告,配有环境变量配置截图以及实验运行及结果详细过程描述与截图
第五天 hadoop2.x中HA机制的原理和全分布式集群安装部署及维护 01-zookeeper.avi 02-zookeeper2.avi 03-NN高可用方案的要点1.avi 04-hadoop-HA机制的配置文件.avi 05-hadoop分布式集群HA模式部署.avi 06-hdfs...
Hadoop运行在Linux系统上,因此,需要学习实践一些常用的Linux命令。本实验旨在熟悉常用的Linux操作,为顺利开展后续其他实验奠定基础。 二、实验环境 Windows 10 VMware Workstation Pro虚拟机 Hadoop环境 Jdk1.8 ...
2. 本书不仅包含了使用Hadoop进行大数据处理的实践性知识和实例,还以图文并茂的形势系统性的揭示了Hadoop技术族中关键组件的运行原理和优化手段,为读者进一步提升Hadoop使用技巧和运行效率提供了颇具价值的参考 ...
针对如上问题,深入分析了Hadoop源代码,理清了Hadoop的运行原理,在Hadoop资源管理机制Yarn中改进了Hadoop任务的排序,建立了新的任务排序规则,提出了对各节点性能评价的指标,分为动态性能指标和静态性能指标。...
本书不仅包含了使用Hadoop进行大数据处理的实践性知识和示例还以图文并茂的形式系统性地揭示了Hadoop技术族中关键组件的运行原理和优化手段为读者进一步提升Hadoop使用技巧和运行效率提供了颇具价值的参考。《Hadoop...
深入解析MapReduce架构设计与实现原理》由Hadoop领域资深的实践者亲自执笔,首先介绍了MapReduce的设计理念和编程模型,然后从源代码的角度深入分析了RPC框架、客户端、JobTracker、TaskTracker和Task等MapReduce...